diff --git a/index.html b/index.html
index 31505b1..b24c3c7 100644
--- a/index.html
+++ b/index.html
@@ -1280,7 +1280,11 @@ body.book #toc,body.book #preamble,body.book h1.sect0,body.book .sect1>h2{page-b
19.20.4.3.1. What is the coherency protocol implemented by the classic cache system in gem5?
-19.20.4.4. gem5 event queue TimingSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs
+19.20.4.4. gem5 event queue AtomicSimpleCPU syscall emulation freestanding example analysis with caches and multiple CPUs
+
+
19.20.4.5. gem5 event queue MinorCPU syscall emulation freestanding example analysis
19.20.4.6. gem5 event queue DerivO3CPU syscall emulation freestanding example analysis
@@ -1389,7 +1393,11 @@ body.book #toc,body.book #preamble,body.book h1.sect0,body.book .sect1>h2{page-b
-21.1.2. C multithreading
+21.1.2. C multithreading
+
+
21.1.3. GCC C extensions
- 21.1.3.1. C empty struct
@@ -1403,7 +1411,11 @@ body.book #toc,body.book #preamble,body.book h1.sect0,body.book .sect1>h2{page-b
- 21.2.1. C++ initialization types
- 21.2.2. C++ multithreading
@@ -2006,16 +2018,21 @@ body.book #toc,body.book #preamble,body.book h1.sect0,body.book .sect1>h2{page-b
- 32.1. Hardware threads
- 32.2. Cache coherence
@@ -6670,6 +6687,23 @@ asdf=qwer
+
+
As of the Linux kernel v5.7 (possibly earlier, I’ve skipped a few releases), boot also shows the init arguments and environment very clearly, which is a great addition:
+
+
+
<6>[ 0.309984] Run /sbin/init as init process
+<7>[ 0.309991] with arguments:
+<7>[ 0.309997] /sbin/init
+<7>[ 0.310004] nokaslr
+<7>[ 0.310010] -
+<7>[ 0.310016] with environment:
+<7>[ 0.310022] HOME=/
+<7>[ 0.310028] TERM=linux
+<7>[ 0.310035] earlyprintk=pl011,0x1c090000
+<7>[ 0.310041] lkmc_home=/lkmc
+
+
@@ -18568,14 +18608,36 @@ getconf _NPROCESSORS_CONF
+
+
+-
+
sysconf with userland/linux/sysconf.c
-
./run --cpus 2 --emulator gem5 --userland userland/linux/sysconf.c | grep _SC_NPROCESSORS_ONLN
-./run --cpus 2 --emulator gem5 --userland userland/cpp/thread_hardware_concurrency.cpp
+
./run --cpus 2 --emulator gem5 --userland userland/linux/sysconf.c | grep _SC_NPROCESSORS_ONLN
+
+-
+
C++ multithreading's userland/cpp/thread_hardware_concurrency.cpp:
+
+
+
./run --cpus 2 --emulator gem5 --userland userland/cpp/thread_hardware_concurrency.cpp
+
+
+-
+
direct access to several special filesystem files that contain this information e.g. via userland/c/cat.c:
+
+
+
./run --cpus 2 --emulator gem5 --userland userland/c/cat.c --cli-args /proc/cpuinfo
+
+
+
+
+
Disables debug symbols (no -g) for some reason.
+
+
@@ -21325,7 +21390,7 @@ cat "$(./getvar --arch aarch64 --emulator gem5 trace_txt_file)"
This is the simplest of all protocols, and therefore the first one you should study to learn how Ruby works.
+
+
Tested on gem5 08c79a194d1a3430801c04f37d13216cc9ec1da3.
@@ -22127,7 +22202,7 @@ for module in modules.keys():
And from IPDB we see that this appears to loop over every object string of type m5.objects.modulename.
-
This init gets called from src/python/importer.py at the exec:
+
This __init__ gets called from src/python/importer.py at the exec:
-
-
+
It would be amazing to analyze a simple example with interconnect packets possibly invalidating caches of other CPUs.
@@ -24357,20 +24429,22 @@ type=SetAssociative
If we don’t use such instructions that flush memory, we would only see the interconnect at work when caches run out.
./run \
--arch aarch64 \
- --cli-args '2 100' \
+ --cli-args '2 10' \
--cpus 3 \
--emulator gem5 \
- --gem5-worktree master3 \
- --userland userland/cpp/atomic/aarch64_add.cpp \
+ --trace FmtFlag,Cache,DRAM,ExecAll,XBar \
+ --userland userland/c/atomic.c \
+ -- \
+ --caches \
;
@@ -24383,6 +24457,218 @@ type=SetAssociative
Figure 5. config.dot.svg for a system with two TimingSimpleCPU with caches.
+
+
Once again we focus on the shared function region my_thread_main which is where the interesting cross core memory collisions will be happening.
+
+
As a maybe-not-so-interesting, we have a look at the very first my_thread_main icache hit points:
+
+
+
93946000: Cache: system.cpu1.icache: access for ReadReq [8b0:8b3] IF miss
+93946000: Cache: system.cpu1.icache: createMissPacket: created ReadCleanReq [880:8bf] IF from ReadReq [8b0:8b3] IF
+93946000: Cache: system.cpu1.icache: handleAtomicReqMiss: Sending an atomic ReadCleanReq [880:8bf] IF
+93946000: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[5] packet ReadCleanReq [880:8bf] IF
+93946000: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[5] packet ReadCleanReq [880:8bf] IF SF size: 1 lat: 1
+93946000: Cache: system.cpu0.icache: handleSnoop: snoop hit for ReadCleanReq [880:8bf] IF, old state is state: 7 (E) valid: 1 writable: 1 readable: 1 dirty: 0 | tag: 0 set: 0x22 way: 0
+93946000: Cache: system.cpu0.icache: new state is state: 5 (S) valid: 1 writable: 0 readable: 1 dirty: 0 | tag: 0 set: 0x22 way: 0
+93946000: DRAM: system.mem_ctrls: recvAtomic: ReadCleanReq 0x880
+93946000: Cache: system.cpu1.icache: handleAtomicReqMiss: Receive response: ReadResp [880:8bf] IF in state 0
+93946000: Cache: system.cpu1.icache: Block addr 0x880 (ns) moving from state 0 to state: 5 (S) valid: 1 writable: 0 readable: 1 dirty: 0 | tag: 0 set: 0x22 way: 0
+93946000: ExecEnable: system.cpu1: A0 T0 : @my_thread_main : sub sp, sp, #48 : IntAlu : D=0x0000003fffd6b9a0 flags=(IsInteger)
+93946500: Cache: system.cpu1.icache: access for ReadReq [8b4:8b7] IF hit state: 5 (S) valid: 1 writable: 0 readable: 1 dirty: 0 | tag: 0 set: 0x22 way: 0
+93946500: Cache: system.cpu1.dcache: access for WriteReq [a19a8:a19af] hit state: f (M) valid: 1 writable: 1 readable: 1 dirty: 1 | tag: 0x14 set: 0x66 way: 0
+93946500: ExecEnable: system.cpu1: A0 T0 : @my_thread_main+4 : str x0, [sp, #8] : MemWrite : D=0x0000007ffffefc70 A=0x3fffd6b9a8 flags=(IsInteger|IsMemRef|IsStore)
+
+
+
+-
+
the physical address for my_thread_main is at 0x8b0, which gets requested is a miss, since it is the first time CPU1 goes near that region, since CPU1 was previously executing in standard library code far from our text segment
+
+-
+
CPU0 already has has that cache line (0x880) in its cache at state E of MOESI, so it snoops and moves to S. We can look up the logs to see exactly where CPU0 had previously read that address:
+
+
+
table: 1, dirty: 0
+59135500: Cache: system.cpu0.icache: Block addr 0x880 (ns) moving from state 0 to state: 7 (E) valid: 1 writable: 1 readable: 1 dirty: 0 | tag: 0 set: 0x22 way: 0
+59135500: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[1] packet WritebackClean [8880:88bf]
+59135500: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[1] packet WritebackClean [8880:88bf] SF size: 0 lat: 1
+59135500: DRAM: system.mem_ctrls: recvAtomic: WritebackClean 0x8880
+59135500: ExecEnable: system.cpu0: A0 T0 : @frame_dummy : stp
+
+
+-
+
the request does touch RAM, it does not get served by the other cache directly. CPU1 is now also at state S for the block
+
+-
+
the second cache request from CPU1 is 4 bytes further ahead 0x8b4, and this time it is of course a hit.
+
+
Since this is an STR, it also does a dcache access, to 0xA19A8 in this case near its stack SP, and it is a hit, which is not surprising, since basically stack accesses are the very first thing any C code does, and there must be some setup code running on CPU1 before my_thread_main.
+
+
+
+
+
93952500: Cache: system.cpu1.icache: access for ReadReq [8d4:8d7] IF hit state: 7 (E) valid: 1 writable: 1 readable: 1 dirty: 0 | tag: 0 set: 0x23 way: 0
+93952500: Cache: system.cpu1.dcache: access for ReadReq [2060:2063] miss
+93952500: Cache: system.cpu1.dcache: createMissPacket: created ReadSharedReq [2040:207f] from ReadReq [2060:2063]
+93952500: Cache: system.cpu1.dcache: handleAtomicReqMiss: Sending an atomic ReadSharedReq [2040:207f]
+93952500: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[6] packet ReadSharedReq [2040:207f]
+93952500: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[6] packet ReadSharedReq [2040:207f] SF size: 0 lat: 1
+93952500: DRAM: system.mem_ctrls: recvAtomic: ReadSharedReq 0x2040
+93952500: Cache: system.cpu1.dcache: handleAtomicReqMiss: Receive response: ReadResp [2040:207f] in state 0
+93952500: Cache: system.cpu1.dcache: Block addr 0x2040 (ns) moving from state 0 to state: 7 (E) valid: 1 writable: 1 readable: 1 dirty: 0 | tag: 0 set: 0x81 way: 0
+93952500: ExecEnable: system.cpu1: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000000 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
+
+
+
so we determine its physical address of 0x2060. It was a miss, and then it went into E.
+
+
So we look ahead to the following accesses to that physical address, before CPU2 reaches that point of the code and starts making requests as well.
+
+
First there is the STR for the first LDR which is of course a hit:
+
+
+
93954500: Cache: system.cpu1.dcache: access for WriteReq [2060:2063] hit state: 7 (E) valid: 1 writable: 1 readable: 1 dirty: 0 | tag: 0 set: 0x81 way: 0
+93954500: ExecEnable: system.cpu1: A0 T0 : @my_thread_main+52 : str x1, [x0] : MemWrite : D=0x0000000000000001 A=0x411060 flags=(IsInteger|IsMemRef|IsStore)
+
+
+
If found the line in E, so we presume that it moves it to M. Then the second read confirms that it was in M:
+
+
+
93964500: Cache: system.cpu1.dcache: access for ReadReq [2060:2063] hit state: f (M) valid: 1 writable: 1 readable: 1 dirty: 1 | tag: 0 set: 0x81 way: 0
+93964500: ExecEnable: system.cpu1: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000001 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
+
+
+
Now let’s jump to when CPU2 starts making requests.
+
+
The first time this happens is on its first LDR at:
+
+
+
94058500: Cache: system.cpu2.dcache: access for ReadReq [2060:2063] miss
+94058500: Cache: system.cpu2.dcache: createMissPacket: created ReadSharedReq [2040:207f] from ReadReq [2060:2063]
+94058500: Cache: system.cpu2.dcache: handleAtomicReqMiss: Sending an atomic ReadSharedReq [2040:207f]
+94058500: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[10] packet ReadSharedReq [2040:207f]
+94058500: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[10] packet ReadSharedReq [2040:207f] SF size: 1 lat: 1
+94058500: Cache: system.cpu1.dcache: handleSnoop: snoop hit for ReadSharedReq [2040:207f], old state is state: f (M) valid: 1 writable: 1 readable: 1 dirty: 1 | tag: 0 set: 0x81 way: 0
+94058500: Cache: system.cpu1.dcache: new state is state: d (O) valid: 1 writable: 0 readable: 1 dirty: 1 | tag: 0 set: 0x81 way: 0
+94058500: CoherentXBar: system.membus: recvAtomicBackdoor: Not forwarding ReadSharedReq [2040:207f]
+94058500: Cache: system.cpu2.dcache: handleAtomicReqMiss: Receive response: ReadResp [2040:207f] in state 0
+94058500: Cache: system.cpu2.dcache: Block addr 0x2040 (ns) moving from state 0 to state: 5 (S) valid: 1 writable: 0 readable: 1 dirty: 0 | tag: 0 set: 0x81 way: 0
+94058500: ExecEnable: system.cpu2: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000009 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
+
+
+
+-
+
CPU1 moves from M to O
+
+-
+
CPU2 moves from I to S
+
+
+
+
It also appears that no DRAM was accessed since there are no logs for it, so did the XBar get the value directly from the other cache? TODO: why did the earlier 93946000: DRAM read happened then, since CPU0 had the line when CPU1 asked for it?
+
+
The above log sequence also makes it clear that it is the XBar that maintains coherency: it appears that the CPU2 caches tells the XBar what it is doing, and then the XBar tells other caches on other CPUs about it, which leads CPU1 to move to O.
+
+
Then CPU1 hits its LDR on O:
+
+
+
94060500: Cache: system.cpu1.dcache: access for ReadReq [2060:2063] hit state: d (O) valid: 1 writable: 0 readable: 1 dirty: 1 | tag: 0 set: 0x81 way: 0
+94060500: ExecEnable: system.cpu1: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000009 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
+
+
+
and then CPU2 writes moving to M and moving CPU1 to I:
+
+
+
94060500: Cache: system.cpu2.dcache: access for WriteReq [2060:2063] hit state: 5 (S) valid: 1 writable: 0 readable: 1 dirty: 0 | tag: 0 set: 0x81 way: 0
+94060500: Cache: system.cpu2.dcache: createMissPacket: created UpgradeReq [2040:207f] from WriteReq [2060:2063]
+94060500: Cache: system.cpu2.dcache: handleAtomicReqMiss: Sending an atomic UpgradeReq [2040:207f]
+94060500: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[10] packet UpgradeReq [2040:207f]
+94060500: CoherentXBar: system.membus: recvAtomicBackdoor: src system.membus.slave[10] packet UpgradeReq [2040:207f] SF size: 1 lat: 1
+94060500: Cache: system.cpu1.dcache: handleSnoop: snoop hit for UpgradeReq [2040:207f], old state is state: d (O) valid: 1 writable: 0 readable: 1 dirty: 1 | tag: 0 set: 0x81 way: 0
+94060500: Cache: system.cpu1.dcache: new state is state: 0 (I) valid: 0 writable: 0 readable: 0 dirty: 0 | tag: 0xffffffffffffffff set: 0x81 way: 0
+94060500: CoherentXBar: system.membus: recvAtomicBackdoor: Not forwarding UpgradeReq [2040:207f]
+94060500: Cache: system.cpu2.dcache: handleAtomicReqMiss: Receive response: UpgradeResp [2040:207f] in state 5
+94060500: Cache: system.cpu2.dcache: Block addr 0x2040 (ns) moving from state 5 to state: f (M) valid: 1 writable: 1 readable: 1 dirty: 1 | tag: 0 set: 0x81 way: 0
+94060500: ExecEnable: system.cpu2: A0 T0 : @my_thread_main+52 : str x1, [x0] : MemWrite : D=0x000000000000000a A=0x411060 flags=(IsInteger|IsMemRef|IsStore)
+
+
+
and so on, they just keep fighting over that address and changing one another’s state.
+
+
+
+
+
Since we have fully understood coherency in that previous example, it should now be easier to understand what is going on with Ruby:
+
+
+
+
./run \
+ --arch aarch64 \
+ --cli-args '2 10' \
+ --cpus 3 \
+ --emulator gem5 \
+ --trace FmtFlag,DRAM,ExecAll,Ruby \
+ --userland userland/c/atomic.c \
+ -- \
+ --cpu-type AtomicSimpleCPU \
+ --ruby \
+;
+
+
+
+
Note that now the --trace Cache,XBar flags have no effect, since Ruby replaces those classic memory model components entirely with the Ruby version, so we enable the Ruby flag version instead. Note however that this flag is very verbose and produces about 10x more output than the classic memory experiment.
+
+
+
Also remember that ARM’s default Ruby protocol is 'MOESI_CMP_directory'.
+
+
+
First we note that the output of the experiment is the same:
+
+
+
+
atomic 20
+non-atomic 19
+
+
+
+
@@ -27059,6 +27345,13 @@ cd ../..
+
+time.h
+
+
@@ -27240,23 +27546,100 @@ echo 1 > /proc/sys/vm/overcommit_memory
-
+
+
+
+
+
Demonstrates atomic_int and thrd_create.
+
+
+
Disassembly with GDB at LKMC 619fef4b04bddc4a5a38aec5e207dd4d5a25d206 + 1:
+
+
+
+
./run-toolchain \
+ --arch aarch64 gdb \
+ -- \
+ -batch \
+ -ex 'disas/rs my_thread_main' $(./getvar \
+ --arch aarch64 userland_build_dir)/c/atomic.out \
+;
+
+
+
+
+
+
16 ++cnt;
+ 0x00000000004008cc <+28>: 80 00 00 b0 adrp x0, 0x411000 <malloc@got.plt>
+ 0x00000000004008d0 <+32>: 00 80 01 91 add x0, x0, #0x60
+ 0x00000000004008d4 <+36>: 00 00 40 b9 ldr w0, [x0]
+ 0x00000000004008d8 <+40>: 01 04 00 11 add w1, w0, #0x1
+ 0x00000000004008dc <+44>: 80 00 00 b0 adrp x0, 0x411000 <malloc@got.plt>
+ 0x00000000004008e0 <+48>: 00 80 01 91 add x0, x0, #0x60
+ 0x00000000004008e4 <+52>: 01 00 00 b9 str w1, [x0]
+
+17 ++acnt;
+ 0x00000000004008e8 <+56>: 20 00 80 52 mov w0, #0x1 // #1
+ 0x00000000004008ec <+60>: e0 1b 00 b9 str w0, [sp, #24]
+ 0x00000000004008f0 <+64>: e0 1b 40 b9 ldr w0, [sp, #24]
+ 0x00000000004008f4 <+68>: e2 03 00 2a mov w2, w0
+ 0x00000000004008f8 <+72>: 80 00 00 b0 adrp x0, 0x411000 <malloc@got.plt>
+ 0x00000000004008fc <+76>: 00 70 01 91 add x0, x0, #0x5c
+ 0x0000000000400900 <+80>: 03 00 e2 b8 ldaddal w2, w3, [x0]
+ 0x0000000000400904 <+84>: 61 00 02 0b add w1, w3, w2
+ 0x0000000000400908 <+88>: e0 03 01 2a mov w0, w1
+ 0x000000000040090c <+92>: e0 1f 00 b9 str w0, [sp, #28]
+
+
+
+
+
+-
+
the atomic increment uses ldadd
+
+-
+
the non-atomic increment just does LDR, ADD, STR: ldadd
+
+
+
+
+
+
+
16 ++cnt;
+ 0x0000000000400a00 <+32>: 60 00 40 b9 ldr w0, [x3]
+ 0x0000000000400a04 <+36>: 00 04 00 11 add w0, w0, #0x1
+ 0x0000000000400a08 <+40>: 60 00 00 b9 str w0, [x3]
+
+17 ++acnt;
+ 0x0000000000400a0c <+44>: 20 00 80 52 mov w0, #0x1 // #1
+ 0x0000000000400a10 <+48>: 40 00 e0 b8 ldaddal w0, w0, [x2]
+
+
+
+
so the situation is the same but without all the horrible stack noise.
+
+
@@ -27338,6 +27721,16 @@ echo 1 > /proc/sys/vm/overcommit_memory
+
+virtual and polymorphism
+
+
@@ -27691,6 +28084,111 @@ time ./mutex.out 4 100000000
+
+
+
+
The smallest data race we managed to come up as of LKMC 7c01b29f1ee7da878c7cc9cb4565f3f3cf516a92 and gem5 872cb227fdc0b4d60acc7840889d567a6936b6e1 was with userland/c/atomic.c (see also C multithreading):
+
+
+
+
./run \
+ --arch aarch64 \
+ --cli-args '2 10' \
+ --cpus 3 \
+ --emulator gem5 \
+ --userland userland/c/atomic.c \
+;
+
+
+
+
+
+
atomic 20
+non-atomic 19
+
+
+
+
/run -aA -eg -u userland/c/atomic.c --cli-args '2 200' --cpus 3 --userland-build-id o3 -N1 --trace ExecAll — --caches --cpu-type TimingSimpleCPU
+
Note that that the system is very minimal, and doesn’t even have caches, so I’m curious as to how this can happen at all.
+
+
+
So first we do a run with --trace Exec and look at the my_thread_main entries.
+
+
+
From there we see that first CPU1 enters the function, since it was spawned first.
+
+
+
Then for some time, both CPU1 and CPU2 are running at the same time.
+
+
+
Finally, CPU1 exists, then CPU2 runs alone for a while to finish its loops, and then CPU2 exits.
+
+
+
By greping the LDR data read from the log, we are able to easily spot the moment where things started to go wrong based on the D= data:
+
+
+
+
grep -E 'my_thread_main\+36' trace.txt > trace-ldr.txt
+
+
+
+
The grep output contains
+
+
+
+
94024500: system.cpu1: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000006 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
+94036500: system.cpu1: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000007 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
+94048500: system.cpu1: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000008 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
+94058500: system.cpu2: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000009 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
+94060500: system.cpu1: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000009 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
+94070500: system.cpu2: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x000000000000000a A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
+94082500: system.cpu2: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x000000000000000b A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
+
+
+
+
and so se see that it is at 94058500 that things started going bad, since two consecutive loads from different CPUs read the same value D=9! Actually, things were not too bad afterwards because this was by coincidence the last CPU1 read, we would have missed many more increments if the number of iterations had been larger.
+
+
+
Now that we have the first bad time, let’s look at the fuller disassembly to better understand what happens around that point.
+
+
+
+
94058500: system.cpu2: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000009 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
+94059000: system.cpu2: A0 T0 : @my_thread_main+40 : add w1, w0, #1 : IntAlu : D=0x000000000000000a flags=(IsInteger)
+94059000: system.cpu1: A0 T0 : @my_thread_main+120 : b.cc <my_thread_main+28> : IntAlu : flags=(IsControl|IsDirectControl|IsCondControl)
+94059500: system.cpu1: A0 T0 : @my_thread_main+28 : adrp x0, #69632 : IntAlu : D=0x0000000000411000 flags=(IsInteger)
+94059500: system.cpu2: A0 T0 : @my_thread_main+44 : adrp x0, #69632 : IntAlu : D=0x0000000000411000 flags=(IsInteger)
+94060000: system.cpu2: A0 T0 : @my_thread_main+48 : add x0, x0, #96 : IntAlu : D=0x0000000000411060 flags=(IsInteger)
+94060000: system.cpu1: A0 T0 : @my_thread_main+32 : add x0, x0, #96 : IntAlu : D=0x0000000000411060 flags=(IsInteger)
+94060500: system.cpu1: A0 T0 : @my_thread_main+36 : ldr x0, [x0] : MemRead : D=0x0000000000000009 A=0x411060 flags=(IsInteger|IsMemRef|IsLoad)
+94060500: system.cpu2: A0 T0 : @my_thread_main+52 : str x1, [x0] : MemWrite : D=0x000000000000000a A=0x411060 flags=(IsInteger|IsMemRef|IsStore)
+
+
+
+
and from this, all becomes crystal clear:
+
+
+
+-
+
94058500: CPU2 loads
+
+-
+
94060500: CPU1 loads
+
+-
+
94060500: CPU2 stores
+
+
+
+
+
so we see that CPU2 just happened to store after CPU1 loads.
+
+
+
We also understand why LDADD solves the race problem in AtomicSimpleCPU: it does the load and store in one single go!
+
+
@@ -27700,6 +28198,9 @@ time ./mutex.out 4 100000000
TODO let’s understand that fully one day.
+
+
In simple terms, when a certain group of caches of different CPUs are coherent, reads on one core always see the writes previously made by other cores. TODO: is it that strict, or just ordering? TODO what about simultaneous read and writes?
+
+
+-
+
guarantees eventual write propagation
+
+-
+
guarantees a single order of all writes to same location
+
+-
+
no guarantees on when writes propagate
+
+
+
+
And notably it contrasts that with Memory consistency, which according to them is about ordering requirements on different addresses.
+
Algorithms to keep the caches of different cores of a system coherent. Only matters for multicore systems.
@@ -38275,13 +38804,25 @@ west build -b qemu_aarch64 samples/hello_world
The main software use case example to have in mind is that of multiple threads incrementing an atomic counter as in userland/cpp/atomic/std_atomic.cpp, see also: atomic.cpp. Then, if one processors writes to the cache, other processors have to know about it before they read from that address.
-
Note that cache coherency only applies to memory read/write instructions that explicitly make coherency requirements.
-
-
In most ISAs, this tends to be the minority of instructions, and is only used when something is going to modify memory that is known to be shared across threads. For example, the a x86 LOCK would be used to increment atomic counters that get incremented across several threads. Outside of those cases, cache coherency is not guaranteed, and behaviour is undefined.
+
Even if caches are coherent, this is still not enough to avoid data race conditions, because this does not enforce atomicity of read modify write sequences. This is for example shown at: Detailed gem5 analysis of how data races happen.
+
Either they can snoop only control, or both control and data can be snooped.
@@ -38296,7 +38837,7 @@ west build -b qemu_aarch64 samples/hello_world
-
+
@@ -38543,7 +39084,7 @@ west build -b qemu_aarch64 samples/hello_world
-
+
@@ -38855,7 +39396,7 @@ CACHE2 S nyy
TODO gem5 concrete example.
-
+
TODO understand well why those are needed.
@@ -38875,7 +39416,7 @@ CACHE2 S nyy
-
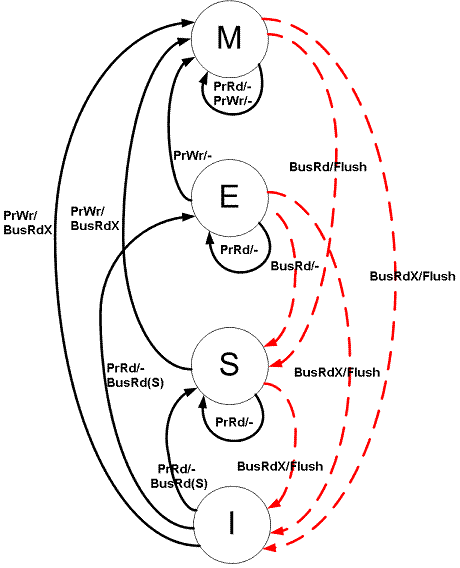
This is a common case on read write modify loops. On MSI, it would first do PrRd, send BusRd (to move any M to S), get data, and go to Shared, then PrWr must send BusUpgr to invalidate other Shared and move to M.
+
This is a common case on read write modify loops. On MSI, it would:
+
+
+-
+
first do PrRd
+
+-
+
send BusRd (to move any M to S), get data, and go to Shared
+
+-
+
then PrWr must send BusUpgr to invalidate other Shared and move to M
+
+
-
With MESI, the PrRd could go to E instead of S depending on who services it. If it does go to E, then the PrWr only moves it to M, there is no need to send BusUpgr because we know that no one else is in S.
+
With MESI:
+
+
+-
+
the PrRd could go to E instead of S depending on who services it
+
+-
+
if it does go to E, then the PrWr only moves it to M, there is no need to send BusUpgr because we know that no one else is in S
+
+
gem5 12c917de54145d2d50260035ba7fa614e25317a3 has two Ruby MESI models implemented: MESI_Two_Level and MESI_Three_Level.
-
+
In MSI, it feels wasteful that an MS transaction needs to flush to memory: why do we need to flush right now, since even more caches now have that data? Why not wait until later ant try to gain something from this deferral?
@@ -38969,7 +39536,7 @@ CACHE2 S nyy
gem5 12c917de54145d2d50260035ba7fa614e25317a3 has several Ruby MOESI models implemented: MOESI_AMD_Base, MOESI_CMP_directory, MOESI_CMP_token and MOESI_hammer.
{kind=link}